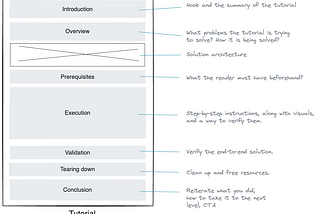
PinnedDunith DanushkainLevel Up CodingCrafting Clarity: How To Structure a Perfect Technical Tutorial?What are the key sections of a tutorial intended for a technical audience? What information should go in there?Jan 8Jan 8
PinnedDunith DanushkainTributary DataThe State of Data Infrastructure Landscape in 2022 and BeyondKey trends to expect in the data infrastructure domain in 2022 and beyond.Jan 10, 2022Jan 10, 2022
PinnedDunith DanushkainTributary DataEvent-driven APIs — Understanding the PrinciplesWhat are event-driven APIs? How do they differ from REST APIs? What technology choices are there to build them?Apr 26, 20215Apr 26, 20215
PinnedDunith DanushkainTributary Data5 Reasons Why You Should Use Microsoft Dapr to Build Event-driven MicroservicesWhy Dapr excels at building distributed, loosely-coupled, event-driven MicroservicesMar 16, 20212Mar 16, 20212
PinnedDunith DanushkainTributary DataA Gentle Introduction to Event-driven Change Data CaptureHow to detect, capture, and propagate changes in source databases to target systems in real-time, event-driven mannerApr 20, 20214Apr 20, 20214
Dunith DanushkainTowards Data ScienceReal-Time Analytics Solution for Usage-Based API Billing and MeteringDesign a real-time analytics pipeline for tracking API invocation usage with Apache APISIX, Redpanda, and Apache Pinot.May 24May 24
Dunith DanushkainLevel Up CodingA Beginners Guide to Kafka Schema RegistryWhy do Kafka developers need a schema registry for message serialization and deserialization? How it works and what benefits it provides?Apr 302Apr 302
Dunith DanushkainLevel Up CodingA Beginner’s Guide to Data Serialization SystemsLearn how data serialization, schemas, and schema registries help in consistently exchanging data between different systems.Apr 24Apr 24
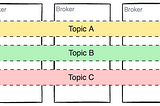
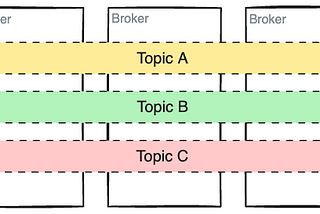
Dunith DanushkainLevel Up CodingA Gentle Introduction to Kafka APIA vendor-neutral and language-agnostic beginners guide to fundamentals of Kafka API and its information hierarchy.Apr 142Apr 142
Dunith DanushkainLevel Up CodingUnderstanding the Claim-Check PatternEfficiently Handling Large Message Payloads without Overloading the Message BusApr 2Apr 2